输入格式:
每个输入包含 1 个测试用例,即一个不超过 1000 位的正整数 N。
输出格式:
对 N 中每一种不同的个位数字,以 D:M 的格式在一行中输出该位数字 D 及其在 N 中出现的次数 M。要求按 D 的升序输出。
输入样例:
1 | 100311 |
输出样例:
1 | 0:2 |
题解:
1 | n = input() |
每个输入包含 1 个测试用例,即一个不超过 1000 位的正整数 N。
对 N 中每一种不同的个位数字,以 D:M 的格式在一行中输出该位数字 D 及其在 N 中出现的次数 M。要求按 D 的升序输出。
1 | 100311 |
1 | 0:2 |
1 | n = input() |
月饼是中国人在中秋佳节时吃的一种传统食品,不同地区有许多不同风味的月饼。现给定所有种类月饼的库存量、总售价、以及市场的最大需求量,请你计算可以获得的最大收益是多少。
注意:销售时允许取出一部分库存。样例给出的情形是这样的:假如我们有 3 种月饼,其库存量分别为 18、15、10 万吨,总售价分别为 75、72、45 亿元。如果市场的最大需求量只有 20 万吨,那么我们最大收益策略应该是卖出全部 15 万吨第 2 种月饼、以及 5 万吨第 3 种月饼,获得 72 + 45/2 = 94.5(亿元)。
每个输入包含一个测试用例。每个测试用例先给出一个不超过 1000 的正整数 N 表示月饼的种类数、以及不超过 500(以万吨为单位)的正整数 D 表示市场最大需求量。随后一行给出 N 个正数表示每种月饼的库存量(以万吨为单位);最后一行给出 N 个正数表示每种月饼的总售价(以亿元为单位)。数字间以空格分隔。
对每组测试用例,在一行中输出最大收益,以亿元为单位并精确到小数点后 2 位。
1 | 3 20 |
1 | 94.50 |
1 | kind, need = map(int, input().split()) |
给定任一个各位数字不完全相同的 4 位正整数,如果我们先把 4 个数字按非递增排序,再按非递减排序,然后用第 1 个数字减第 2 个数字,将得到一个新的数字。一直重复这样做,我们很快会停在有“数字黑洞”之称的 6174,这个神奇的数字也叫 Kaprekar 常数。
例如,我们从6767开始,将得到
1 | 7766 - 6677 = 1089 |
现给定任意 4 位正整数,请编写程序演示到达黑洞的过程。
输入给出一个 (0,104) 区间内的正整数 N。
如果 N 的 4 位数字全相等,则在一行内输出 N - N = 0000;否则将计算的每一步在一行内输出,直到 6174 作为差出现,输出格式见样例。注意每个数字按 4 位数格式输出。
1 | 6767 |
1 | 7766 - 6677 = 1089 |
1 | 2222 |
1 | 2222 - 2222 = 0000 |
1 | a = input().zfill(4) |
大家应该都会玩“锤子剪刀布”的游戏:两人同时给出手势,胜负规则如图所示:
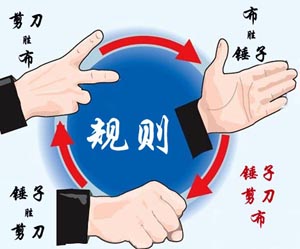
现给出两人的交锋记录,请统计双方的胜、平、负次数,并且给出双方分别出什么手势的胜算最大。
输入第 1 行给出正整数 N(≤105),即双方交锋的次数。随后 N 行,每行给出一次交锋的信息,即甲、乙双方同时给出的的手势。C 代表“锤子”、J 代表“剪刀”、B 代表“布”,第 1 个字母代表甲方,第 2 个代表乙方,中间有 1 个空格。
输出第 1、2 行分别给出甲、乙的胜、平、负次数,数字间以 1 个空格分隔。第 3 行给出两个字母,分别代表甲、乙获胜次数最多的手势,中间有 1 个空格。如果解不唯一,则输出按字母序最小的解。
1 | 10 |
1 | 5 3 2 |
此方法暂时没找到问题所在,第一个测试点答案错误 18分 希望发现问题的朋友能够指点一下
1 | n = int(input()) |
此方法为C语言 满分
1 |
|
正整数 A 的“DA(为 1 位整数)部分”定义为由 A 中所有 DA 组成的新整数 PA。例如:给定 A=3862767,DA=6,则 A 的“6 部分”PA 是 66,因为 A 中有 2 个 6。
现给定 A、DA、B、DB,请编写程序计算 PA+PB。
输入在一行中依次给出 A、DA、B、DB,中间以空格分隔,其中 0<A,B<109。
在一行中输出 PA+PB 的值。
1 | 3862767 6 13530293 3 |
1 | 399 |
1 | 3862767 1 13530293 8 |
1 | 0 |
1 | A,Da,B,Db = map(str,input().split()) |
宋代史学家司马光在《资治通鉴》中有一段著名的“德才论”:“是故才德全尽谓之圣人,才德兼亡谓之愚人,德胜才谓之君子,才胜德谓之小人。凡取人之术,苟不得圣人,君子而与之,与其得小人,不若得愚人。”
现给出一批考生的德才分数,请根据司马光的理论给出录取排名。
输入第一行给出 3 个正整数,分别为:N(≤105),即考生总数;L(≥60),为录取最低分数线,即德分和才分均不低于 L 的考生才有资格被考虑录取;H(<100),为优先录取线——德分和才分均不低于此线的被定义为“才德全尽”,此类考生按德才总分从高到低排序;才分不到但德分到线的一类考生属于“德胜才”,也按总分排序,但排在第一类考生之后;德才分均低于 H,但是德分不低于才分的考生属于“才德兼亡”但尚有“德胜才”者,按总分排序,但排在第二类考生之后;其他达到最低线 L 的考生也按总分排序,但排在第三类考生之后。
随后 N 行,每行给出一位考生的信息,包括:准考证号 德分 才分,其中准考证号为 8 位整数,德才分为区间 [0, 100] 内的整数。数字间以空格分隔。
输出第一行首先给出达到最低分数线的考生人数 M,随后 M 行,每行按照输入格式输出一位考生的信息,考生按输入中说明的规则从高到低排序。当某类考生中有多人总分相同时,按其德分降序排列;若德分也并列,则按准考证号的升序输出。
1 | 14 60 80 |
1 | 12 |
1 |
|
大侦探福尔摩斯接到一张奇怪的字条:
1 | 我们约会吧! |
大侦探很快就明白了,字条上奇怪的乱码实际上就是约会的时间星期四 14:04,因为前面两字符串中第 1 对相同的大写英文字母(大小写有区分)是第 4 个字母 D,代表星期四;第 2 对相同的字符是 E ,那是第 5 个英文字母,代表一天里的第 14 个钟头(于是一天的 0 点到 23 点由数字 0 到 9、以及大写字母 A 到 N 表示);后面两字符串第 1 对相同的英文字母 s 出现在第 4 个位置(从 0 开始计数)上,代表第 4 分钟。现给定两对字符串,请帮助福尔摩斯解码得到约会的时间。
输入在 4 行中分别给出 4 个非空、不包含空格、且长度不超过 60 的字符串。
在一行中输出约会的时间,格式为 DAY HH:MM,其中 DAY 是某星期的 3 字符缩写,即 MON 表示星期一,TUE 表示星期二,WED 表示星期三,THU 表示星期四,FRI 表示星期五,SAT 表示星期六,SUN 表示星期日。题目输入保证每个测试存在唯一解。
1 | 3485djDkxh4hhGE |
1 | THU 14:04 |
1 | s1 = input() |
令 Pi 表示第 i 个素数。现任给两个正整数 M≤N≤104,请输出 PM 到 PN 的所有素数。
输入在一行中给出 M 和 N,其间以空格分隔。
输出从 PM 到 PN 的所有素数,每 10 个数字占 1 行,其间以空格分隔,但行末不得有多余空格。
1 | 5 27 |
1 | 11 13 17 19 23 29 31 37 41 43 |
1 |
|
给定一系列正整数,请按要求对数字进行分类,并输出以下 5 个数字:
每个输入包含 1 个测试用例。每个测试用例先给出一个不超过 1000 的正整数 N,随后给出 N 个不超过 1000 的待分类的正整数。数字间以空格分隔。
对给定的 N 个正整数,按题目要求计算 A1~A5 并在一行中顺序输出。数字间以空格分隔,但行末不得有多余空格。
若其中某一类数字不存在,则在相应位置输出 N。
1 | 13 1 2 3 4 5 6 7 8 9 10 20 16 18 |
1 | 30 11 2 9.7 9 |
1 | 8 1 2 4 5 6 7 9 16 |
1 | N 11 2 N 9 |
1 | num = map(int , input().split()[1:]) |